Apache Spark – Core Programming
Spark Core is the base of the whole project. It provides distributed task dispatching, scheduling, and basic I/O functionalities. Spark uses a specialized fundamental data structure known as RDD (Resilient Distributed Datasets) that is a logical collection of data partitioned across machines. RDDs can be created in two ways; one is by referencing datasets in external storage systems and second is by applying transformations (e.g. map, filter, reducer, join) on existing RDDs.
The RDD abstraction is exposed through a language-integrated API. This simplifies programming complexity because the way applications manipulate RDDs is similar to manipulating local collections of data.
Spark Shell
Spark provides an interactive shell − a powerful tool to analyze data interactively. It is available in either Scala or Python language. Spark’s primary abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). RDDs can be created from Hadoop Input Formats (such as HDFS files) or by transforming other RDDs.
Open Spark Shell
The following command is used to open Spark shell.
$ spark-shell
Create simple RDD
Let us create a simple RDD from the text file. Use the following command to create a simple RDD.
scala> val inputfile = sc.textFile(“input.txt”)
The output for the above command is
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12
The Spark RDD API introduces few Transformations and few Actions to manipulate RDD.
RDD Transformations
RDD transformations returns pointer to new RDD and allows you to create dependencies between RDDs. Each RDD in dependency chain (String of Dependencies) has a function for calculating its data and has a pointer (dependency) to its parent RDD.
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example.
Therefore, RDD transformation is not a set of data but is a step in a program (might be the only step) telling Spark how to get data and what to do with it.
Given below is a list of RDD transformations.
| S.No | Transformations & Meaning |
|---|---|
| 1 | map(func)Returns a new distributed dataset, formed by passing each element of the source through a function func. |
| 2 | filter(func)Returns a new dataset formed by selecting those elements of the source on which func returns true. |
| 3 | flatMap(func)Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| 4 | mapPartitions(func)Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> ⇒ Iterator<U> when running on an RDD of type T. |
| 5 | mapPartitionsWithIndex(func)Similar to map Partitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) ⇒ Iterator<U> when running on an RDD of type T. |
| 6 | sample(withReplacement, fraction, seed)Sample a fraction of the data, with or without replacement, using a given random number generator seed. |
| 7 | union(otherDataset)Returns a new dataset that contains the union of the elements in the source dataset and the argument. |
| 8 | intersection(otherDataset)Returns a new RDD that contains the intersection of elements in the source dataset and the argument. |
| 9 | distinct([numTasks])Returns a new dataset that contains the distinct elements of the source dataset. |
| 10 | groupByKey([numTasks])When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs.Note − If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. |
| 11 | reduceByKey(func, [numTasks])When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V, V) ⇒ V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral “zero” value. Allows an aggregated value type that is different from the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| 13 | sortByKey([ascending], [numTasks])When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the Boolean ascending argument. |
| 14 | join(otherDataset, [numTasks])When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks])When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called group With. |
| 16 | cartesian(otherDataset)When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| 17 | pipe(command, [envVars])Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process’s stdin and lines output to its stdout are returned as an RDD of strings. |
| 18 | coalesce(numPartitions)Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. |
| 19 | repartition(numPartitions)Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. |
| 20 | repartitionAndSortWithinPartitions(partitioner)Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
Actions
The following table gives a list of Actions, which return values.
| S.No | Action & Meaning |
|---|---|
| 1 | reduce(func)Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| 2 | collect()Returns all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| 3 | count()Returns the number of elements in the dataset. |
| 4 | first()Returns the first element of the dataset (similar to take (1)). |
| 5 | take(n)Returns an array with the first n elements of the dataset. |
| 6 | takeSample (withReplacement,num, [seed])Returns an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| 7 | takeOrdered(n, [ordering])Returns the first n elements of the RDD using either their natural order or a custom comparator. |
| 8 | saveAsTextFile(path)Writes the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark calls toString on each element to convert it to a line of text in the file. |
| 9 | saveAsSequenceFile(path) (Java and Scala)Writes the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop’s Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| 10 | saveAsObjectFile(path) (Java and Scala)Writes the elements of the dataset in a simple format using Java serialization, which can then be loaded using SparkContext.objectFile(). |
| 11 | countByKey()Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| 12 | foreach(func)Runs a function func on each element of the dataset. This is usually, done for side effects such as updating an Accumulator or interacting with external storage systems.Note − modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |
Programming with RDD
Let us see the implementations of few RDD transformations and actions in RDD programming with the help of an example.
Example
Consider a word count example − It counts each word appearing in a document. Consider the following text as an input and is saved as an input.txt file in a home directory.
input.txt − input file.
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
Follow the procedure given below to execute the given example.
Open Spark-Shell
The following command is used to open spark shell. Generally, spark is built using Scala. Therefore, a Spark program runs on Scala environment.
$ spark-shell
If Spark shell opens successfully then you will find the following output. Look at the last line of the output “Spark context available as sc” means the Spark container is automatically created spark context object with the name sc. Before starting the first step of a program, the SparkContext object should be created.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Create an RDD
First, we have to read the input file using Spark-Scala API and create an RDD.
The following command is used for reading a file from given location. Here, new RDD is created with the name of inputfile. The String which is given as an argument in the textFile(“”) method is absolute path for the input file name. However, if only the file name is given, then it means that the input file is in the current location.
scala> val inputfile = sc.textFile("input.txt")
Execute Word count Transformation
Our aim is to count the words in a file. Create a flat map for splitting each line into words (flatMap(line ⇒ line.split(“ ”)).
Next, read each word as a key with a value ‘1’ (<key, value> = <word,1>)using map function (map(word ⇒ (word, 1)).
Finally, reduce those keys by adding values of similar keys (reduceByKey(_+_)).
The following command is used for executing word count logic. After executing this, you will not find any output because this is not an action, this is a transformation; pointing a new RDD or tell spark to what to do with the given data)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);
Current RDD
While working with the RDD, if you want to know about current RDD, then use the following command. It will show you the description about current RDD and its dependencies for debugging.
scala> counts.toDebugString
Caching the Transformations
You can mark an RDD to be persisted using the persist() or cache() methods on it. The first time it is computed in an action, it will be kept in memory on the nodes. Use the following command to store the intermediate transformations in memory.
scala> counts.cache()
Applying the Action
Applying an action, like store all the transformations, results into a text file. The String argument for saveAsTextFile(“ ”) method is the absolute path of output folder. Try the following command to save the output in a text file. In the following example, ‘output’ folder is in current location.
scala> counts.saveAsTextFile("output")
Checking the Output
Open another terminal to go to home directory (where spark is executed in the other terminal). Use the following commands for checking output directory.
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1 part-00000 part-00001 _SUCCESS
The following command is used to see output from Part-00000 files.
[hadoop@localhost output]$ cat part-00000
Output
(people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
The following command is used to see output from Part-00001 files.
[hadoop@localhost output]$ cat part-00001
Output
(walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
UN Persist the Storage
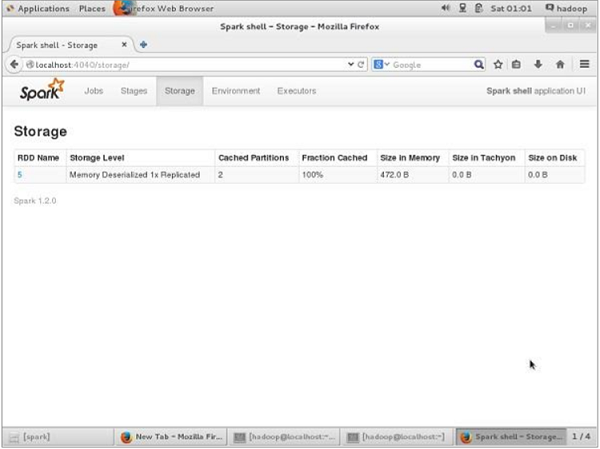
Before UN-persisting, if you want to see the storage space that is used for this application, then use the following URL in your browser.
http://localhost:4040
You will see the following screen, which shows the storage space used for the application, which are running on the Spark shell.
If you want to UN-persist the storage space of particular RDD, then use the following command.
Scala> counts.unpersist()
You will see the output as follows −
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list 15/06/27 00:57:33 INFO BlockManager: Removing RDD 9 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810) 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106) res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14
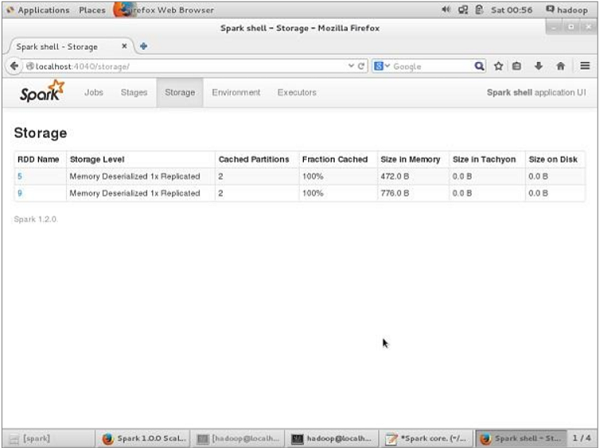
For verifying the storage space in the browser, use the following URL.
http://localhost:4040/
You will see the following screen. It shows the storage space used for the application, which are running on the Spark shell.